

In mid-2018 we were approached by one of the largest online tutoring companies in China to assist with their data analytics. While they were busy building a large analytics team of their own, they had a particular challenge in the creation of Curriculum Maps for their courses.
A Curriculum Map is a metadata-rich representation of the set of learning objectives in a course. It is the framework on which most subsequent data analysis is based. The level of accuracy of the curriculum map will be critical to the quality of many of the other components of a personalised learning experience.
Why a traditional approach would not work
For most courses we have worked on, the design of a curriculum map starts with the author or subject-matter-expert (SME). They list the learning objectives of the course using a simple spreadsheet or a dedicated tool, such as the Adaptemy Curriculum Designer. They then add further metadata to enrich the map with known prerequisites, learning object types, exam levels etc.
The challenge for this company was that instead of designing their online courses based on learning objectives, they used a content ingestion engine to generate and tag content items from existing third-party courses. Therefore they had very large numbers of content items but no authoring expertise.
On the positive side though, they have one of the largest datasets we have come across, with over 30 million students using their content. By using standardised tracking of content usage and learner behaviours, there was easily sufficient data for our analytics team to take on this challenge.
Criteria of a good curriculum map
The first challenge of a good curriculum map is to define each node or learning objective at the appropriate level of granularity. Each learning objective needs to be independently assessable, but excessive decomposition results in exponential growth in data requirements, making the map less accurate for a given dataset.
The second challenge of a good curriculum map is to find the relationships between all of the nodes within the map, and to assign accurate weightings to these links.
Machine Learning approach
There were 3 phases to this project:
- Import and clean the Learner Records data
- Distinguish the set of Learning Objectives (nodes) in the course
- Learn the relationships between the nodes
With any customer, it is important to understand exactly the format and definitions of the data we receive. Typically referred to as the Learner Record Store, some standards such as xAPI exist, but even these contain ambiguous definitions that need to be clarified. Most of the clarifications in this project were around repeated attempts by students, ignoring low-effort sessions, and how multi-part questions were recorded.
Distinguishing the set of Learning Objectives in a course starts with some existing content structures e.g. topics and sections. From there we explore similarity measures using factor analysis and conditional independence tests for Bayesian networks, and our analytics team apply judgement in this phase to arrive at a granularity that suits the expected application of the curriculum map by the product designer.
The most specialised algorithms are dedicated to learning the relationships between the nodes in the map, and this is where we have the most experience. By mining the answer patterns of students, we find the dependencies between all pairs of nodes in the network. As there can be up to a million node-pairs in some courses, this requires very large data sets of student records.
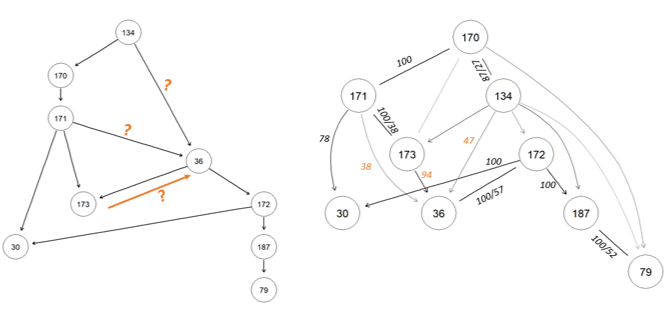
The final stage is the optimisation of the topology (or shape) of the network. By retaining only the stronger relationships and simplifying the network, we can arrive at a Curriculum Map that is a good balance between accuracy and practicality of implementation.
Ongoing improvements
No matter how you arrive at your first version of your Curriculum Map, the good news is that the map continues to improve itself based on subsequent Learner Data.
This process may be curated by a Subject Matter Expert, or may be a periodic automated update, depending on the customer needs. In this project, we did not complete any integration with the customer’s live systems, but instead conducted offline analytics on their dataset and provided the completed Curriculum Map to be used by their own platform.
Dig deeper into the algorithms
More information on the concepts and algorithms can be found in this post: How Do We Update The Curriculum Model?
Your data analytics needs
If you have any challenge you’d like to set our Data Analytics team, please get in touch and we’ll see what we can do! Especially if you already gather learning data in some structured format, you can start to discover patterns in the data that will enable you to improve your learning products.

